Recrutement : comment intégrer un Data Scientist ?
Parole d'expert

Le métier de Data Scientist a évolué ces dernières années. Intégrer un profil de ce type dans une organisation est un vrai défi. Bruno Sarrant, Data Scientist (actuaire de formation et ancien consultant Java) qui intervient auprès de grands groupes dans le cadre de projets de Data Science, nous donne sa vision sur l’évolution de ce métier riche, complexe et passionnant à la fois.
Évolution du métier de Data Scientist
Naissance du Data Scientist
Le Data Scientist est né grâce à la démocratisation des ordinateurs dans les institutions, les entreprises et chez les particuliers. La popularisation d’Internet a permis d’accroître les ressources (stockage & puissance de calcul). Il a été ainsi possible de travailler sur des algorithmes inaccessibles auparavant. On a vu émerger le féru de mathématiques, qui cherchait le St Graal en se basant sur le « Numerical Recipes » ; le jeune bidouilleur fou, qui créait des représentations graphiques en assembleur.
Évolution du métier
Le déploiement des solutions de gestion de données massives, que l’on résume sous le terme « Big Data » et de son paradigme 3VC (Volume, Variété, Vélocité, Complexité) a demandé à nos proto Data Scientists d’évoluer car :
- Les méthodes d’analyse statistiques classiques se basent sur le seuil d’acceptation « p » et avec un tel volume il devient de plus en plus difficile de rejeter les hypothèses.
- Les données récupérées demandent de plus en plus de connaissance de type IT pour arriver à y accéder, les manipuler et les affiner.
- Le Business a beaucoup évolué. Il ne se contente plus d’avoir des prédictions, il veut avoir des prescriptions pour conquérir de nouveaux clients et tenir ses engagements vis-à-vis des actionnaires.
C’est ainsi que le « Data Scientist 2.0 » est apparu au grand jour (NDR : aux yeux des comités de direction…) après la publication en 2012 de l’article de Thomas H. Davenport et D.J. Patil. Cet article a consacré le terme de « Data Scientist », individu à la croisée entre des expertises en Mathématiques, Informatique et Business, souvent décrit à l’aide du diagramme de Venn ci-dessous.
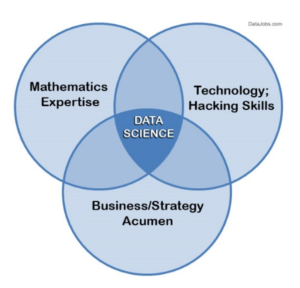
Figure 1 : Diagramme de Venn représentant la superposition des prérequis nécessaires pour faire de la Data Science 2.0
Ascension du Data Scientist 2.0
Les « Data Scientist 2.0 » ont réussi à émerger grâce à plusieurs facteurs :
- Un environnement technique très mouvant avec une démocratisation d’une offre dématérialisée, tant au niveau de la puissance de calcul (Instances Spark, Fermes GPU…) que de la gestion d’importants volumes de données (Parc Hadoop géré via Ambari, déploiement d’instances packagées…),
- Le développement de nouvelles méthodes d’analyses, grâce aux nouveaux environnements collaboratifs (Github, Stackoverflow, Kaggle …) et basées nativement sur ces nouveaux environnements techniques,
- L’émergence d’une offre de formations spécialisées Big Data / Data Science soit par les institutions (Universités, organismes professionnels …), soit par de nouvelles plateformes (Coursera, Udacity …)
- L’apparition d’un nouveau fleuron industriel avec les GAFAs et diverses licornes, qui ont fait de la Data Science, une des clés de voute de leurs stratégies marketing et communication.
Tous ces éléments ont amené un flot de communication, afin que l’inconscient collectif (des décideurs) intègre l’importance de la Data Science en tant que facteur positif de valeur ajoutée et, donc, de revenus futurs. Pour illustrer ce point, Gartner corroborait l’avènement de la Data Science dans son fameux Hype Cycle en 2014.
Le recrutement d’un Data Scientist
Aujourd’hui, tout le monde veut monter une équipe avec les meilleurs sur le marché pour être les leaders sur leurs segments. C’est un mythe qui circule (trop) au sein des comités de direction car pour un Data Scientist 2.0, vos entreprises sont « has been » et les meilleurs sont chez les GAFAs et autre Licornes.
Donc il reste au niveau de l’offre :
- Quelques expérimentés qui ont une partie des trois expertises de notre diagramme de Venn, mais qui ne sont pas typés « Data Science» ou bien qui ne communiquent pas
- Des jeunes diplômés qui ont baigné au cours de leurs études sur la partie Technologie et une vision « disruptive » du Business,
- Ou bien beaucoup de Proto Data Scientists qui peuvent répondre à votre besoin, à la condition d’être formés.
Au niveau de la demande, on constate que :
- il y a un problème dans la prospection des profils car les recruteurs (chasseurs de têtes, direction RH) ont plus l’habitude de chercher les gens qui rentrent dans les cases… Alors que les entreprises ont besoin d’innover et donc de profils atypiques,
- Les prix proposés sont généralement en inadéquation car les entreprises ne réalisent pas à quel point ce marché est compétitif,
- L’image de l’entreprise peut être désuète par rapport à la communication qui est faite dans le domaine de la Data Science, ce qui peut être répulsif pour un Data Scientist 2.0 car il gère aussi sa carrière.
Conclusion :
- On constate en général une inadéquation offre-demande tant dans le prix que dans l’identification des ressources possibles,
- Les recrutements sont insatisfaisants pour les deux parties,
- La compétitivité ambiante ne permet pas de stabiliser vos équipes car vos concurrents viennent débaucher chez vous.
Pour éviter une telle situation, il est impératif de bien analyser votre besoin, de le segmenter correctement et d’identifier les ressources critiques pour y apporter un traitement spécifique
Les caractéristiques d’un Datascientist
La disruption
Si vous vous documentez sur le phénomène de la Data Science 2.0, un mot clé ressort souvent : la disruption. Ce qui signifie « faire la révolution » si l’on fait dans un raccourci du style « café du commerce ». Votre Data Scientist 2.0 baigne dans cette idéologie et cela peut poser un vrai souci d’intégration au sein d’une entreprise pérenne, stable, fortement hiérarchisée et avec un niveau de régulation plus ou moins fort.
La compétition
De plus, votre Data Scientist 2.0 baigne dans une ambiance de compétition permanente car il faut trouver l’algorithme le plus performant, notamment s’il est féru des compétitions Kaggle. Et pour y arriver, il a besoin de liberté de mouvements et d’actions, il veut être indépendant et ne pas être limité. Ceci va forcément poser un problème dans une structure où il faut l’approbation de ses supérieurs pour faire, obtenir les ressources et changer les processus opérationnels.
Le partage
Le troisième point est que votre Data Scientist 2.0 communique et beaucoup. Il partage avec ses « pairs » sur Stackoverflow ou Slack, participe à des projets open source pour monter son tracking record et n’hésite pas à se poser en tant que référence ultime lors de débats internes. Il veut bien faire et il le fait savoir. Ceci peut poser un vrai problème d’intégration avec ses clients internes si cela devient excessif. Mais aussi un problème de confidentialité car communiquer à l’extérieur peut amener à faire des confidences sur le fonctionnement de votre entreprise et de ses projets en cours.
Ces trois éléments peuvent produire, dans l’excès, à l’apparition de comportements aberrants qui peuvent déstabiliser votre organisation. Ce sont des traits que l’on peut retrouver dans la psychologie de certains traders au cours de la période 2000-2010 et qui ont amené les banques à consolider des pertes conséquentes, faute d’avoir canalisé correctement ces opérateurs en les contrôlant efficacement.
Comment réussir son intégration?
Pour arriver à intégrer un Data Scientist dans votre organisation, il faut que les deux parties aient des vertus et comportements qui les rapprochent.
Côté Data Scientist :
- L’empathie: modéliser demande avant tout d’écouter pour comprendre le domaine et les spécificités de l’entreprise et du marché.
- Le travail en équipe : rien n’égale le résultat d’une équipe où la cohésion règne. Le challenge permet de construire et d’avancer.
- L’humilité : pour évoluer dans des structures hiérarchisées.
- La passion d’apprendre : elle permet d’avancer malgré les lenteurs d’une structure.
Et du côté de l’entreprise :
- Un recrutement disruptif : un data scientist est là pour créer de l’innovation, pour porter un regard neuf sur votre structure, pour vous fournir de la matière grise. Le processus pour l’identifier et l’évaluer sera donc bien différent que pour un commercial ou un top manager.
- Une segmentation de vos besoins: le mouton à 5 pattes est très rare et souvent pris chez les meilleurs. Segmenter vous permettra d’identifier le profil idéal entre Communication, Statistiques, Programmation et Business comme le montre le diagramme de Venn, légèrement modifié.
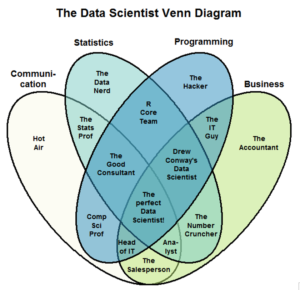
- Une introspection : des proto data scientist, vous en avez plus que vous pensez. Cependant, il faut voir les gens avec une autre perspective.
- Une identification de vos ressources critiques : c’est le plus grand danger, tant en dépendance qu’en source d’erreur de modélisation critique.
- Un investissement à long terme : il ne faut pas attendre un ROI à court terme mais investir sur plusieurs années.
En conclusion
Intégrer un Data Scientist dans une structure est un challenge de taille mais indispensable pour certaines structures afin de continuer à se développer… voire survivre ! C’est toute la stratégie de l’entreprise qui en est impactée.
Pour aller plus loin, consultez l’article dédié à la Data Science ou contactez Bruno Sarrant